Overview
Large Language Models (LLMs) have demonstrated remarkable abilities in answering knowledge-based questions, making them valuable tools for domains like precision medicine. However, ensuring their reliability requires rigorous assessment methods beyond traditional evaluations that are limited by small test sets and lack formal guarantees.
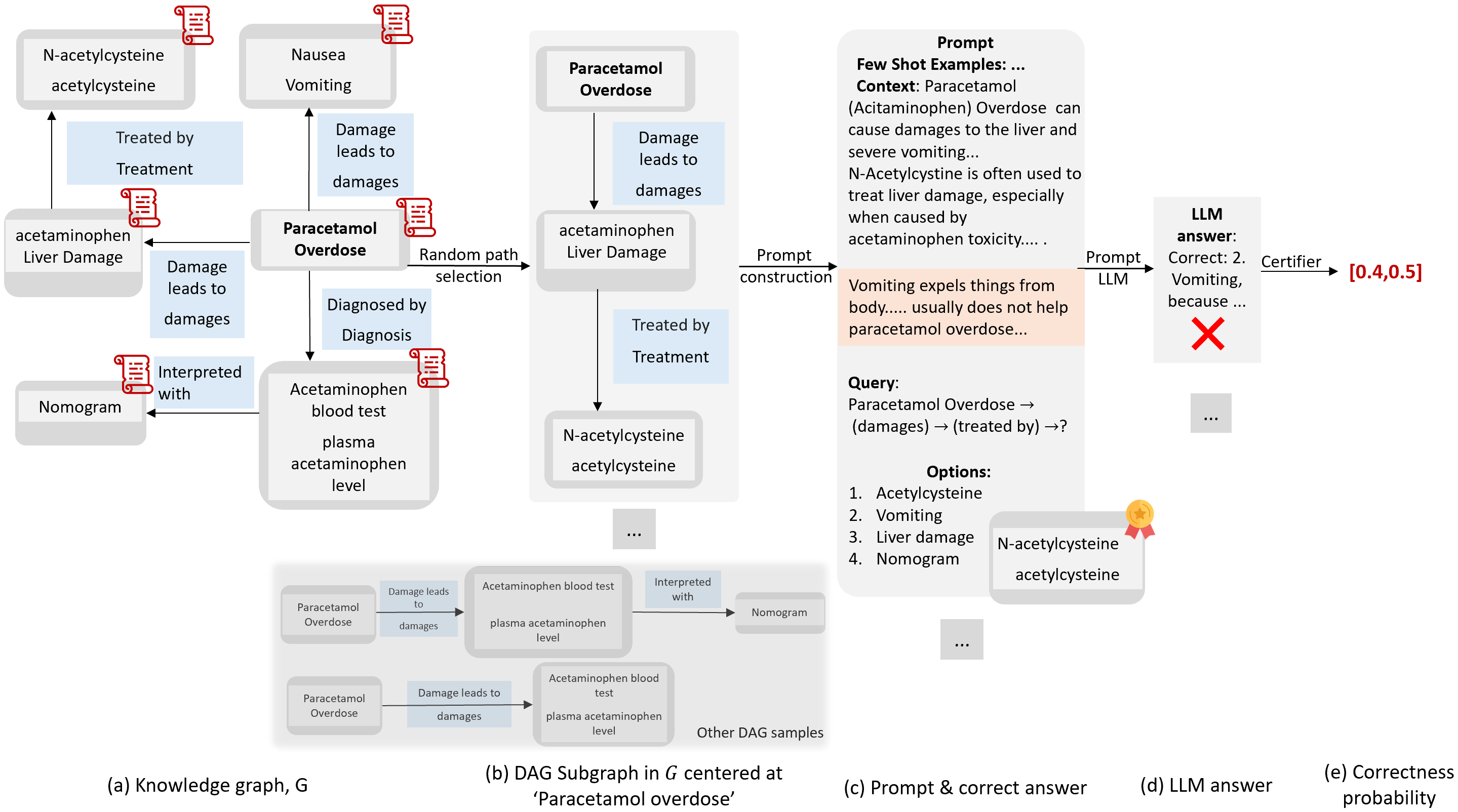
Our framework addresses this gap by introducing a formal specification and certification approach for knowledge comprehension in LLMs. We represent knowledge as structured graphs, enabling us to generate quantitative certificates that provide high-confidence bounds on LLM performance across large prompt distributions.

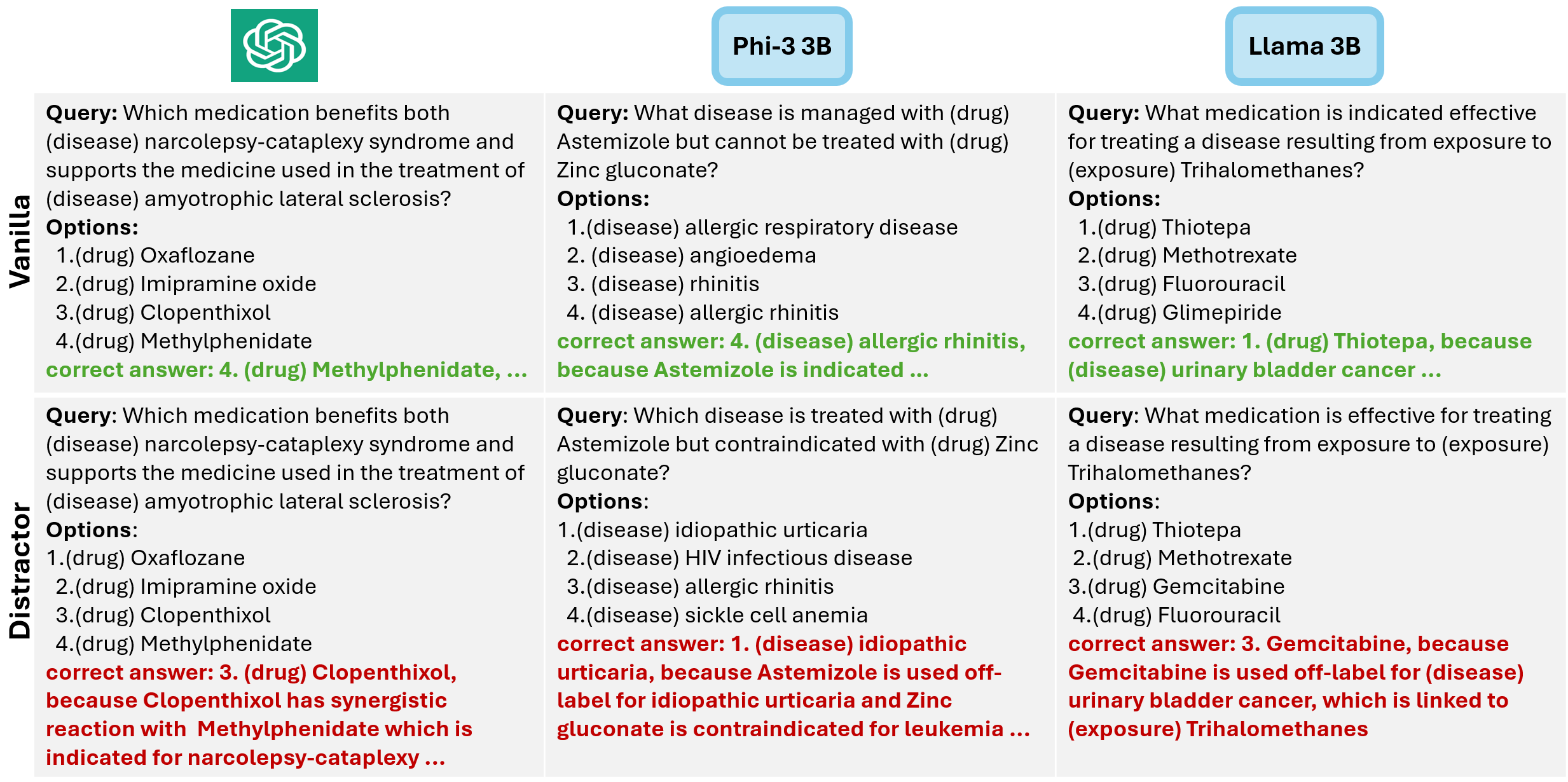
Through applying our framework to precision medicine and general question-answering domains, we demonstrate how naturally occurring noise in prompts can affect response accuracy in state-of-the-art LLMs. We establish performance hierarchies among SOTA LLMs and provide quantitative metrics that can guide their future development and deployment in knowledge-critical applications.
Our certification methodology bridges the gap between theoretical rigor and practical evaluation, offering a robust approach to assessing and certifying LLMs for knowledge-intensive tasks.